近日,杭州的Deepseek公司猶如一顆重磅炸彈,在春節前夕震撼了整個科技投資界,引發了華爾街的軒然大波。
Deepseek推出的開源AI模型,在多個關鍵指標上超越了OpenAI的同類產品,而其研發成本僅為600萬美元,相比之下,OpenAI則花費了數十億美元。這一消息迅速在業界傳開,引發了對AI研發模式的深刻反思。

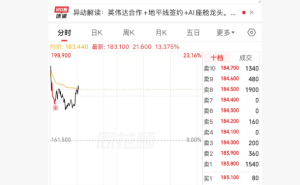
Deepseek的崛起,讓華爾街的投資者們開始質疑,以往那些斥巨資購買顯卡以構建大型AI模型的做法是否明智。是否算力堆砌的背后,隱藏著不為人知的泡沫?這一擔憂迅速蔓延,導致美股科技巨頭的股價集體跳水,其中英偉達一夜之間暴跌17%,市值蒸發超過4萬億元。博通、AMD、微軟、臺積電等科技巨頭也未能幸免,市場普遍認為,AI領域的估值邏輯可能正在發生深刻變化。
Deepseek的成功,讓人們看到了低成本、高效率AI研發模式的可能性。然而,就在業界準備追隨Deepseek的腳步時,馬斯克旗下的xAI公司卻給出了截然不同的答案。
xAI公司發布了名為Grok 3的新大模型,在LMSYS盲測和AIME競賽中均表現出色,馬斯克自豪地宣稱其為全球最聰明的AI。Grok 3的最大亮點在于其龐大的算力支持,堆砌了20萬張H100顯卡,用實際行動詮釋了“大力出奇跡”的真諦。

Grok 3的成功,不僅證明了馬斯克在AI領域的深厚底蘊,也再次驗證了規模定律的有效性。在AI領域,算力仍然是決定模型能力的關鍵因素之一。只要有足夠的顯卡和算力支持,大模型的能力就能得到顯著提升。因此,盡管Deepseek的低成本模式令人眼前一亮,但持續投入芯片、數據中心和云基礎設施仍然是硬道理。
值得注意的是,Grok 3的成功并未讓Deepseek的光芒黯淡。相反,它激發了業界對于AI研發模式的更多思考。在未來的AI領域,低成本與高效率并重,或許將成為新的發展趨勢。然而,無論采用何種模式,算力都將是不可或缺的基石。